

Bem vindo ao Debian Stretch!
Ontem, 17 de junho de 2017, o Debian 9 (Stretch) foi lan ado. Eu gostaria de falar sobre alguns procedimentos b sicos e regras para migrar do Debian 8 (Jessie).
Passos iniciais
- A primeira coisa a fazer ler a nota de lan amento. Isso fundamental para saber sobre poss veis bugs e situa es especiais.
- O segundo passo atualizar o Jessie totalmente antes de migrar para o Stretch. Para isso, ainda dentro do Debian 8, execute os seguintes comandos:
# apt-get update
# apt-get dist-upgrade
Migrando
- Edite o arquivo /etc/apt/sources.list e altere todos os nomes jessie para stretch. A seguir, um exemplo do conte do desse arquivo (poder variar, de acordo com as suas necessidades):
deb http://ftp.br.debian.org/debian/ stretch main
deb-src http://ftp.br.debian.org/debian/ stretch main
deb http://security.debian.org/ stretch/updates main
deb-src http://security.debian.org/ stretch/updates main
# apt-get update
# apt-get dist-upgrade
Caso haja algum problema, leia as mensagens de erro e tente resolver o problema. Resolvendo ou n o tal problema, execute novamente o comando:
# apt-get dist-upgrade
Havendo novos problemas, tente resolver. Busque solu es no Google, se for necess rio. Mas, geralmente, tudo dar certo e voc n o dever ter problemas.
Altera es em arquivos de configura o
Quando voc estiver migrando, algumas mensagens sobre altera es em arquivos de configura o poder o ser mostradas. Isso poder deixar alguns usu rios pedidos, sem saber o que fazer. N o entre em p nico.
Existem duas formas de apresentar essas mensagens: via texto puro em shell ou via janela azul de mensagens. O texto a seguir um exemplo de mensagem em shell:
Ficheiro de configura o '/etc/rsyslog.conf'
==> Modificado (por si ou por um script) desde a instala o.
==> O distribuidor do pacote lan ou uma vers o atualizada.
O que deseja fazer? As suas op es s o:
Y ou I : instalar a vers o do pacote do maintainer
N ou O : manter a vers o actualmente instalada
D : mostrar diferen as entre as vers es
Z : iniciar uma shell para examinar a situa o
A a o padr o manter sua vers o atual.
*** rsyslog.conf (Y/I/N/O/D/Z) [padr o=N] ?
A tela a seguir um exemplo de mensagem via janela:

Nos dois casos, recomend vel que voc escolha por instalar a nova vers o do arquivo de configura o. Isso porque o novo arquivo de configura o estar totalmente adaptado aos novos servi os instalados e poder ter muitas op es novas ou diferentes. Mas n o se preocupe, pois as suas configura es n o ser o perdidas. Haver um backup das mesmas. Assim, para shell, escolha a op o "Y" e, no caso de janela, escolha a op o "instalar a vers o do mantenedor do pacote". muito importante anotar o nome de cada arquivo modificado. No caso da janela anterior, trata-se do arquivo
/etc/samba/smb.conf. No caso do shell o arquivo foi o
/etc/rsyslog.conf.
Depois de completar a migra o, voc poder ver o novo arquivo de configura o e o original. Caso o novo arquivo tenha sido instalado ap s uma escolha via shell, o arquivo original (o que voc tinha anteriormente) ter o mesmo nome com a extens o
.dpkg-old. No caso de escolha via janela, o arquivo ser mantido com a extens o
.ucf-old. Nos dois casos, voc poder ver as modifica es feitas e reconfigurar o seu novo arquivo de acordo com as necessidades.
Caso voc precise de ajuda para ver as diferen as entre os arquivos, voc poder usar o comando diff para compar -los. Fa a o diff sempre do arquivo novo para o original. como se voc quisesse ver como fazer com o novo arquivo para ficar igual ao original. Exemplo:
# diff -Naur /etc/rsyslog.conf /etc/rsyslog.conf.dpkg-old
Em uma primeira vista, as linhas marcadas com "+" dever o ser adicionadas ao novo arquivo para que se pare a com o anterior, assim como as marcadas com "-" dever o ser suprimidas. Mas cuidado: normal que haja algumas linhas diferentes, pois o arquivo de configura o foi feito para uma nova vers o do servi o ou aplicativo ao qual ele pertence. Assim, altere somente as linhas que realmente s o necess rias e que voc mudou no arquivo anterior. Veja o exemplo:
+daemon.*;mail.*;\
+ news.err;\
+ *.=debug;*.=info;\
+ *.=notice;*.=warn /dev/xconsole
+*.* @sam
No meu caso, originalmente, eu s alterei a ltima linha. Ent o, no novo arquivo de configura o, s terei interesse em adicionar essa linha. Bem, se foi voc quem fez a configura o anterior, voc saber fazer a coisa certa. Geralmente, n o haver muitas diferen as entre os arquivos.
Outra op o para ver as diferen as entre arquivos o comando mcdiff, que poder ser fornecido pelo pacote mc. Exemplo:
# mcdiff /etc/rsyslog.conf /etc/rsyslog.conf.dpkg-old
Problemas com ambientes e aplica es gr ficas
poss vel que voc tenha algum problema com o funcionamento de ambientes gr ficos, como Gnome, KDE etc, ou com aplica es como o Mozilla Firefox. Nesses casos, prov vel que o problema seja os arquivos de configura o desses elementos, existentes no diret rio home do usu rio. Para verificar, crie um novo usu rio no Debian e teste com ele. Se tudo der certo, fa a um backup das configura es anteriores (ou renomeie as mesmas) e deixe que a aplica o crie uma configura o nova. Por exemplo, para o Mozilla Firefox, v ao diret rio home do usu rio e, com o Firefox fechado, renomeie o diret rio .mozilla para .mozilla.bak, inicie o Firefox e teste.
Est inseguro?
Caso voc esteja muito inseguro, instale um Debian 8, com ambiente gr fico e outras coisas, em uma m quina virtual e migre para Debian 9 para testar e aprender. Sugiro VirtualBox como virtualizador.
Divirta-se!
 Narabu is a new intraframe video codec. You may or may not want to read
part 1
first.
The GPU, despite being extremely more flexible than it was fifteen years
ago, is still a very different beast from your CPU, and not all problems
map well to it performance-wise. Thus, before designing a codec, it's
useful to know what our platform looks like.
A GPU has lots of special functionality for graphics (well, duh), but we'll
be concentrating on the compute shader subset in this context, ie., we
won't be drawing any polygons. Roughly, a GPU (as I understand it!) is built
up about as follows:
A GPU contains 1 20 cores; NVIDIA calls them SMs (shader multiprocessors),
Intel calls them subslices. (Trivia: A typical mid-range Intel GPU contains two cores,
and thus is designated GT2.) One such core usually runs the same program,
although on different data; there are exceptions, but typically, if your
program can't fill an entire core with parallelism, you're wasting energy.
Each core, in addition to tons (thousands!) of registers, also has some
shared memory (also called local memory sometimes, although that term
is overloaded), typically 32 64 kB, which you can think of in two ways:
Either as a sort-of explicit L1 cache, or as a way to communicate
internally on a core. Shared memory is a limited, precious resource in
many algorithms.
Each core/SM/subslice contains about 8 execution units (Intel
calls them EUs, NVIDIA/AMD calls them something else) and some memory
access logic. These multiplex a bunch of threads (say, 32) and run in
a round-robin-ish fashion. This means that a GPU can handle memory stalls
much better than a typical CPU, since it has so many streams to pick from;
even though each thread runs in-order, it can just kick off an operation
and then go to the next thread while the previous one is working.
Each execution unit has a bunch of ALUs (typically 16) and executes code in a SIMD
fashion. NVIDIA calls these ALUs CUDA cores , AMD calls them stream
processors . Unlike on CPU, this SIMD has full scatter/gather support
(although sequential access, especially in certain patterns, is much more efficient
than random access), lane enable/disable so it can work with conditional
code, etc.. The typically fastest operation is a 32-bit float muladd;
usually that's single-cycle. GPUs love 32-bit FP code. (In fact, in some
GPU languages, you won't even have 8-, 16-bit or 64-bit types. This is
annoying, but not the end of the world.)
The vectorization is not exposed to the user in typical code (GLSL has some
vector types, but they're usually just broken up into scalars, so that's a
red herring), although in some programming languages you can get to swizzle
the SIMD stuff internally to gain advantage of that (there's also schemes for
broadcasting bits by voting etc.). However, it is crucially important to
performance; if you have divergence within a warp, this means the GPU needs
to execute both sides of the if. So less divergent code is good.
Such a SIMD group is called a warp by NVIDIA (I don't know if the others have
names for it). NVIDIA has SIMD/warp width always 32; AMD used to be 64 but
is now 16. Intel supports 4 32 (the compiler will autoselect based on a bunch of
factors), although 16 is the most common.
The upshot of all of this is that you need massive amounts of parallelism
to be able to get useful performance out of a CPU. A rule of thumb is that
if you could have launched about a thousand threads for your problem on CPU,
it's a good fit for a GPU, although this is of course just a guideline.
There's a ton of APIs available to write compute shaders. There's CUDA (NVIDIA-only, but the
dominant player), D3D compute (Windows-only, but multi-vendor),
OpenCL (multi-vendor, but highly variable implementation quality),
OpenGL compute shaders (all platforms except macOS, which has too old drivers),
Metal (Apple-only) and probably some that I forgot. I've chosen to go for
OpenGL compute shaders since I already use OpenGL shaders a lot, and this
saves on interop issues. CUDA probably is more mature, but my laptop is
Intel. :-) No matter which one you choose, the programming model looks very
roughly like this pseudocode:
Narabu is a new intraframe video codec. You may or may not want to read
part 1
first.
The GPU, despite being extremely more flexible than it was fifteen years
ago, is still a very different beast from your CPU, and not all problems
map well to it performance-wise. Thus, before designing a codec, it's
useful to know what our platform looks like.
A GPU has lots of special functionality for graphics (well, duh), but we'll
be concentrating on the compute shader subset in this context, ie., we
won't be drawing any polygons. Roughly, a GPU (as I understand it!) is built
up about as follows:
A GPU contains 1 20 cores; NVIDIA calls them SMs (shader multiprocessors),
Intel calls them subslices. (Trivia: A typical mid-range Intel GPU contains two cores,
and thus is designated GT2.) One such core usually runs the same program,
although on different data; there are exceptions, but typically, if your
program can't fill an entire core with parallelism, you're wasting energy.
Each core, in addition to tons (thousands!) of registers, also has some
shared memory (also called local memory sometimes, although that term
is overloaded), typically 32 64 kB, which you can think of in two ways:
Either as a sort-of explicit L1 cache, or as a way to communicate
internally on a core. Shared memory is a limited, precious resource in
many algorithms.
Each core/SM/subslice contains about 8 execution units (Intel
calls them EUs, NVIDIA/AMD calls them something else) and some memory
access logic. These multiplex a bunch of threads (say, 32) and run in
a round-robin-ish fashion. This means that a GPU can handle memory stalls
much better than a typical CPU, since it has so many streams to pick from;
even though each thread runs in-order, it can just kick off an operation
and then go to the next thread while the previous one is working.
Each execution unit has a bunch of ALUs (typically 16) and executes code in a SIMD
fashion. NVIDIA calls these ALUs CUDA cores , AMD calls them stream
processors . Unlike on CPU, this SIMD has full scatter/gather support
(although sequential access, especially in certain patterns, is much more efficient
than random access), lane enable/disable so it can work with conditional
code, etc.. The typically fastest operation is a 32-bit float muladd;
usually that's single-cycle. GPUs love 32-bit FP code. (In fact, in some
GPU languages, you won't even have 8-, 16-bit or 64-bit types. This is
annoying, but not the end of the world.)
The vectorization is not exposed to the user in typical code (GLSL has some
vector types, but they're usually just broken up into scalars, so that's a
red herring), although in some programming languages you can get to swizzle
the SIMD stuff internally to gain advantage of that (there's also schemes for
broadcasting bits by voting etc.). However, it is crucially important to
performance; if you have divergence within a warp, this means the GPU needs
to execute both sides of the if. So less divergent code is good.
Such a SIMD group is called a warp by NVIDIA (I don't know if the others have
names for it). NVIDIA has SIMD/warp width always 32; AMD used to be 64 but
is now 16. Intel supports 4 32 (the compiler will autoselect based on a bunch of
factors), although 16 is the most common.
The upshot of all of this is that you need massive amounts of parallelism
to be able to get useful performance out of a CPU. A rule of thumb is that
if you could have launched about a thousand threads for your problem on CPU,
it's a good fit for a GPU, although this is of course just a guideline.
There's a ton of APIs available to write compute shaders. There's CUDA (NVIDIA-only, but the
dominant player), D3D compute (Windows-only, but multi-vendor),
OpenCL (multi-vendor, but highly variable implementation quality),
OpenGL compute shaders (all platforms except macOS, which has too old drivers),
Metal (Apple-only) and probably some that I forgot. I've chosen to go for
OpenGL compute shaders since I already use OpenGL shaders a lot, and this
saves on interop issues. CUDA probably is more mature, but my laptop is
Intel. :-) No matter which one you choose, the programming model looks very
roughly like this pseudocode:
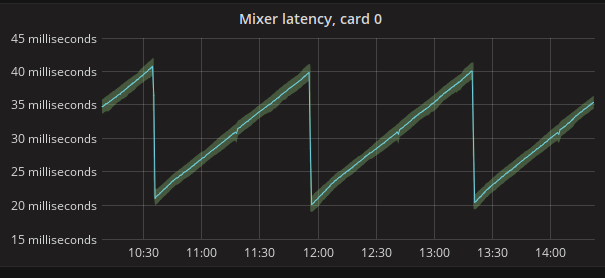 As you can see, the latency goes up, up, up until Nageru figures it's now
safe to drop a frame, and then does it in one clean drop event; no more
hundreds on drops involved. There are very late frame arrivals involved in
this run two extra frame drops, to be precise but the algorithm simply
determines immediately that they are outliers, and drops them without letting
them linger in the queue. (Immediate dropping is usually preferred to
sticking around for a bit and then dropping it later, as it means you only
get one disturbance event in your stream as opposed to two. Of course, you
can only do it if you're reasonably sure it won't lead to more underruns
later.)
Nageru 1.6.1 will ship before
As you can see, the latency goes up, up, up until Nageru figures it's now
safe to drop a frame, and then does it in one clean drop event; no more
hundreds on drops involved. There are very late frame arrivals involved in
this run two extra frame drops, to be precise but the algorithm simply
determines immediately that they are outliers, and drops them without letting
them linger in the queue. (Immediate dropping is usually preferred to
sticking around for a bit and then dropping it later, as it means you only
get one disturbance event in your stream as opposed to two. Of course, you
can only do it if you're reasonably sure it won't lead to more underruns
later.)
Nageru 1.6.1 will ship before 
 There are also corresponding SDI-to-HDMI converters that look pretty much
the same except they convert the other way. (They're easy to confuse, but
that's not a problem unique tothem.)
I've used them for a while now, and there are pros and cons. They seem
reliable enough, and they're 1/4th the price of e.g. Blackmagic's Micro
converters, which is a real bargain. However, there are also some issues:
There are also corresponding SDI-to-HDMI converters that look pretty much
the same except they convert the other way. (They're easy to confuse, but
that's not a problem unique tothem.)
I've used them for a while now, and there are pros and cons. They seem
reliable enough, and they're 1/4th the price of e.g. Blackmagic's Micro
converters, which is a real bargain. However, there are also some issues:

 The only thing that had to stop is leaving our users in the dark on what is happening.
Sorry for the long post, but there are some subjects which are worth writing more than 140 characters about
The only thing that had to stop is leaving our users in the dark on what is happening.
Sorry for the long post, but there are some subjects which are worth writing more than 140 characters about 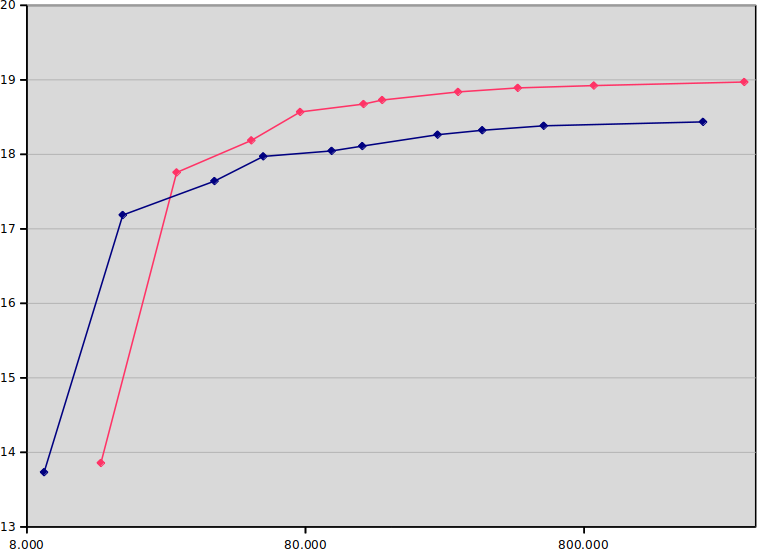 The x-axis is seconds used for the encode (note the logarithmic scale;
placebo takes 200 250 times as long as ultrafast).
The y-axis is SSIM dB, so up and to the left is better. The blue line is
8-bit, and the red line is 10-bit. (I ran most encodes five times and
averaged the results, but it doesn't really matter, due to the logarithmic
scale.)
The results are actually much stronger than I assumed; if you run on
(8-bit) ultrafast or superfast, you should stay with 8-bit, but from there
on, 10-bit is on the Pareto frontier. Actually, 10-bit veryfast (18.187 dB)
is better than 8-bit medium (18.111 dB), while being four times as fast!
But not all of us have a relation to dB quality, so I chose to also do a
test that maybe is a bit more intuitive, centered around bitrate needed for
constant quality. I locked quality to 18 dBm, ie., for each preset, I
adjusted the bitrate until the SSIM showed 18.000 dB plus/minus 0.001 dB.
(Note that this means faster presets get less of a speed advantage, because
they need higher bitrate, which means more time spent entropy coding.)
Then I measured the encoding time (again five times) and graphed the results:
The x-axis is seconds used for the encode (note the logarithmic scale;
placebo takes 200 250 times as long as ultrafast).
The y-axis is SSIM dB, so up and to the left is better. The blue line is
8-bit, and the red line is 10-bit. (I ran most encodes five times and
averaged the results, but it doesn't really matter, due to the logarithmic
scale.)
The results are actually much stronger than I assumed; if you run on
(8-bit) ultrafast or superfast, you should stay with 8-bit, but from there
on, 10-bit is on the Pareto frontier. Actually, 10-bit veryfast (18.187 dB)
is better than 8-bit medium (18.111 dB), while being four times as fast!
But not all of us have a relation to dB quality, so I chose to also do a
test that maybe is a bit more intuitive, centered around bitrate needed for
constant quality. I locked quality to 18 dBm, ie., for each preset, I
adjusted the bitrate until the SSIM showed 18.000 dB plus/minus 0.001 dB.
(Note that this means faster presets get less of a speed advantage, because
they need higher bitrate, which means more time spent entropy coding.)
Then I measured the encoding time (again five times) and graphed the results:
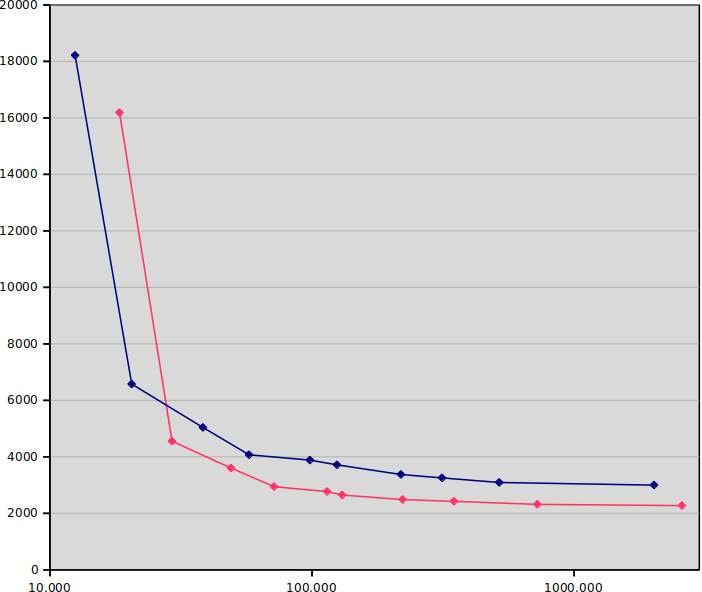 x-axis is again seconds, and y-axis is bitrate needed in kbit/sec, so lower
and to the left is better. Blue is again 8-bit and red is again 10-bit.
If the previous graph was enough to make me intrigued, this is enough to make
me excited. In general, 10-bit gives 20-30% lower bitrate for the same
quality and CPU usage! (Compare this with the supposed up to 50% benefits
of HEVC over H.264, given infinite CPU usage.) The most dramatic example
is when comparing the medium presets directly, where 10-bit runs at
2648 kbit/sec versus 3715 kbit/sec (29% lower bitrate!) and is only 5%
slower. As one progresses towards the slower presets, the gap is somewhat
narrowed (placebo is 27% slower and only 24% lower bitrate), but in the
realistic middle range, the difference is quite marked. If you run 3 Mbit/sec
at 10-bit, you get the quality of 4 Mbit/sec at 8-bit.
So is 10-bit H.264 a no-brainer? Unfortunately, no; the client hardware support
is nearly nil. Not even Skylake, which can do 10-bit HEVC encoding in
hardware (and 10-bit VP9 decoding), can do 10-bit H.264 decoding in hardware.
Worse still, mobile chipsets generally don't support it. There are rumors
that iPhone 6s supports it, but these are unconfirmed; some Android chips
support it, but most don't.
I guess this explains a lot of the limited uptake; since it's in some ways
a new codec, implementers are more keen to get the full benefits of HEVC instead
(even though the licensing situation is really icky). The only ones I know
that have really picked it up as a distribution format is the anime scene,
and they're feeling quite specific pains due to unique content (large
gradients giving pronounced banding in undithered 8-bit).
So, 10-bit H.264: It's awesome, but you can't have it. Sorry :-)
x-axis is again seconds, and y-axis is bitrate needed in kbit/sec, so lower
and to the left is better. Blue is again 8-bit and red is again 10-bit.
If the previous graph was enough to make me intrigued, this is enough to make
me excited. In general, 10-bit gives 20-30% lower bitrate for the same
quality and CPU usage! (Compare this with the supposed up to 50% benefits
of HEVC over H.264, given infinite CPU usage.) The most dramatic example
is when comparing the medium presets directly, where 10-bit runs at
2648 kbit/sec versus 3715 kbit/sec (29% lower bitrate!) and is only 5%
slower. As one progresses towards the slower presets, the gap is somewhat
narrowed (placebo is 27% slower and only 24% lower bitrate), but in the
realistic middle range, the difference is quite marked. If you run 3 Mbit/sec
at 10-bit, you get the quality of 4 Mbit/sec at 8-bit.
So is 10-bit H.264 a no-brainer? Unfortunately, no; the client hardware support
is nearly nil. Not even Skylake, which can do 10-bit HEVC encoding in
hardware (and 10-bit VP9 decoding), can do 10-bit H.264 decoding in hardware.
Worse still, mobile chipsets generally don't support it. There are rumors
that iPhone 6s supports it, but these are unconfirmed; some Android chips
support it, but most don't.
I guess this explains a lot of the limited uptake; since it's in some ways
a new codec, implementers are more keen to get the full benefits of HEVC instead
(even though the licensing situation is really icky). The only ones I know
that have really picked it up as a distribution format is the anime scene,
and they're feeling quite specific pains due to unique content (large
gradients giving pronounced banding in undithered 8-bit).
So, 10-bit H.264: It's awesome, but you can't have it. Sorry :-)